 View figure.
View figure.
DPCL (Dynamic Probe Class Library) is a C++ class library whose application programming interface (API) enables a program to dynamically insert instrumentation code patches, or "probes", into an executing program. The program that uses DPCL calls to insert probes is called the "analysis tool", while the program that accepts and runs the probes is called the "target application".
The DPCL product is an asynchronous software system designed to serve as a foundation for a variety of analysis tools that need to dynamically instrument (insert probes into and remove probes from) target applications. In addition to its API, the DPCL system consists of daemon processes that attach themselves to the target application process(es) to perform most of the actual work, and an asynchronous communication and callback facility that connects the class library to the daemon processes.
This overview describes the various parts of the DPCL system and how they work together to enable analysis tools to instrument target application processes. Before you can understand the individual parts of the DPCL system, however, you need to have a general understanding of the system as a whole. Here is a very high-level description of how an analysis tool uses the DPCL system to instrument a serial or parallel target application. Say you have an executable DPCL program that has been compiled with the DPCL header files and linked with the DPCL library. When you start execution of this program, its code does the following to instrument a target application:
A probe expression is a specific type of data structure called an "abstract syntax tree". Abstract syntax trees (a term used mainly in compiler technology) are data structures that represent instructions removed from a specific syntactic representation; they are a sort of intermediary stage between source code and executable instructions. When the analysis tool calls DPCL functions to insert a probe expression into one or more target application processes, the DPCL system will manipulate these abstract syntax trees into executable instructions that will run as part of the target application process(es).
While an analysis tool can create probe expressions that perform some simple logic, the programmatic capabilities of probe expressions are rather limited. For this reason, a probe expression may optionally call functions. Specifically, a probe expression can call:
There are three general ways an analysis tool can execute probes within a target application process. These three general approaches correspond to the three types of probes -- point probes, phase probes, and one-shot probes. The analysis tool can:
That is a very high-level view of how the analysis tool interacts with the DPCL system in order to instrument a target application. The rest of this overview will provide a more-detailed description of this process and the DPCL system. First, it describes dynamic instrumentation in general by answering the following questions:
Next, this overview describes the basic architecture of the DPCL system by answering the questions:
Once these questions have been answered, you will have a clearer idea of the various parts of the DPCL system, and how they are organized. This overview then concludes by explaining why it is advantageous to build analysis tools on the DPCL system.
Dynamic instrumentation refers to a specific type of software instrumentation. Software instrumentation refers to code that is inserted into a program to gather information regarding the program's run. As the instrumented application executes, the instrumented code then generates the desired information, which could include performance, trace, test coverage, diagnostic, or other data. Traditionally, software instrumentation has been inserted:
Dynamic instrumentation is distinct from these more traditional methods of software instrumentation because it can be added and removed while the application is running. The application does not need to be terminated and restarted from the beginning in order to add and remove instrumentation.
We chose to base the DPCL product on dynamic instrumentation technology, because dynamic instrumentation offers several key benefits that cannot be realized by traditional software instrumentation approaches. Specifically, a DPCL analysis tool's ability to add and remove instrumentation probes while the target application is running means that the analysis tool can perform run-time analysis. In other words, it can examine the target application's behavior without waiting for its execution to complete. This is especially useful for:
Additional advantages of dynamic instrumentation in general, as well as specific advantages of the DPCL system, are described in Why is it advantageous to build analysis tools on the DPCL system?. Before you can fully appreciate the advantages of building analysis tools on the DPCL system, you need to understand more about the DPCL system (as described next in What is the DPCL system?).
The DPCL system is an asynchronous software system whose client/server architecture enables analysis tools to connect to, and insert instrumentation probes into, one or more target application processes. What's more, the DPCL system encapsulates a parallel infrastructure, making it ideally suited for analyzing parallel programs. The DPCL system consists of several conceptual parts including:
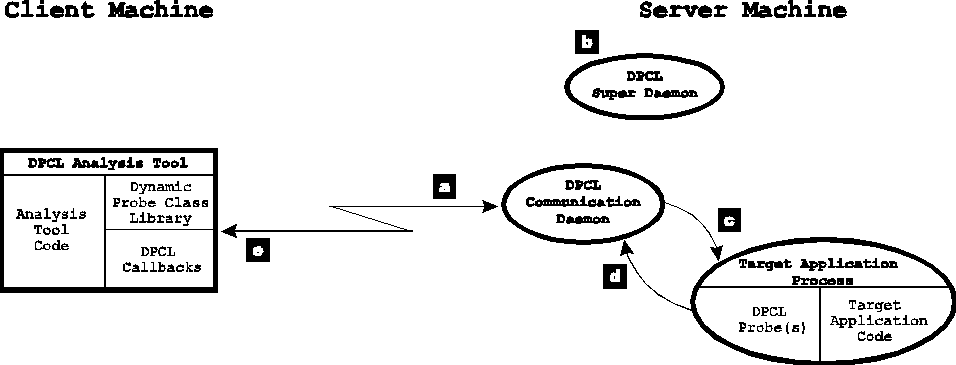
The following figure illustrates how the parts of the DPCL system work together to enable an analysis tool to instrument a serial target application.
Figure 1. Instrumenting a serial target application
| View figure. |
The preceding figure illustrates how the parts of the DPCL system work together to enable an analysis tool to instrument a serial target application. For additional explanation of this figure, refer to the following key:
This next figure is similar to the preceding one, except that it shows how the parts of the DPCL system work together to enable an analysis tool to instrument a parallel target application. The preceding figure's key applies to this next figure as well; refer to it for additional information. Note in this figure that only a single DPCL communication daemon runs, per user, on each server machine. If the analysis tool connects to multiple target application processes running on the same server machine, then that server machine's DPCL communication daemon will coordinate the communication with all of the processes.
Figure 2. Instrumenting a parallel target application
 View figure. View figure. |
The remainder of this section describes each part of the DPCL system (the target application, the analysis tool, the class library, the callbacks, the daemons, and the probes) in greater detail.
A target application is an executable program into which the analysis tool inserts probes. A target application could be a serial or a parallel program. Furthermore, if the target application is a parallel program, it could follow either the Single Program Multiple Data (SPMD) or the Multiple Program Multiple Data (MPMD) model, and may be designed for either a message-passing or a shared-memory system.
An analysis tool (in the context of the DPCL product) is a C++ application that links in the DPCL library and uses the DPCL API calls to instrument (create probes and insert them into) one or more target application processes. In addition to containing code not related to accessing DPCL system functionality (such as defining the user interface), the analysis tool will also contain DPCL callback routines designed to respond to data sent back from the probes it has installed in the target application. Typically, an analysis tool is designed to measure program efficiency, confirm program correctness, or monitor program execution.
The DPCL system is designed to provide you, the creator of analysis tools, with a scalable general-purpose infrastructure for instrumenting target applications. In other words, the DPCL system concentrates on enabling your analysis tool to connect to the target application process(es), and then dynamically insert and remove probes as needed. You concentrate on creating the actual probes, and leverage the DPCL system's ability to insert them into one or more target application processes. What's more, the DPCL system encapsulates a parallel infrastructure, making it ideally suited for analyzing parallel programs. This design affords you a large degree of flexibility. For example, an analysis tool could be a complex and general-purpose tool like a debugger, or it might be a simple and specialized tool designed for only one particular program, user, or situation.
DPCL's Application Programming Interface (API) is the key means by which the analysis tool interacts with the DPCL system to effectively instrument a target application. Along with the DPCL callbacks (which enable an analysis tool to respond asynchronously to data sent from installed probes), the DPCL API is what enables the analysis tool to leverage the capabilities of the DPCL system. The DPCL API contains:
Be aware that the above is just a quick summary of some of the main classes and functional capabilities of the DPCL API. For more information about the DPCL classes, refer to Chapter 2, What are the DPCL classes?. For complete reference information on the DPCL API, refer to the DPCL Class Reference.
There are two types of DPCL API calls -- blocking calls (also referred to as pseudo-synchronous or semi-synchronous service requests) and nonblocking calls (also referred to as asynchronous service requests). Much of the functionality of the DPCL system is available in both blocking and nonblocking versions. For example, to connect to a target application, an analysis tool could call either a blocking function (bconnect) or a nonblocking function (connect). As this example implies, the naming convention for a blocking function is to prefix the letter "b" to the name of the nonblocking function.
To understand why the DPCL API includes both blocking and nonblocking versions of the same functionality, it is important to recall that the DPCL system is an asynchronous system that, by definition, acts upon events that, if they occur, will do so at an undetermined time and in an undetermined order. The nonblocking functions are designed to take advantage of the asynchronous nature of the DPCL system; calls to such functions return immediately without waiting for a response from the DPCL system. When an analysis tool calls an asynchronous, nonblocking function, it can specify the name of a callback routine that will respond to status returned by the DPCL system. The callback not only enables the analysis tool to perform status error checking, but also enables it to be structured in a more event-driven manner. When analyzing parallel programs, certain performance benefits can usually be realized by leveraging the event-driven nature of the asynchronous functions. The Application class, for example, is a grouping of related Process class objects that enables the analysis tool code to manipulate a set of related UNIX processes as a single unit. For the asynchronous Application class functions, the callback routine that responds to the successful or unsuccessful completion of the operation will execute for each process individually. The callback routine, in addition to performing error checking to ensure that the operation was successful for the particular process, could contain code for the next action to be performed on the process. In other words, the analysis tool could continue work on one process without waiting for the operation to complete on the other processes.
The blocking functions, on the other hand, are designed to hide the complexity of the asynchronous system; calls to such functions do not return control to the analysis tool until they either succeed or fail in carrying out the requested service. This means that callbacks are not needed; instead, the code to act upon the function return value can be placed right after to call to the function. Keep in mind, however, that these so-called "blocking" functions are not truly synchronous; instead they merely mimic a synchronous system while allowing the DPCL system to continue processing events not related to the blocking request. For example, data being sent from probes could still be processed by other callback routines while execution is supposedly "blocked" and waiting for the function to return. That is why the blocking functions are referred to as "pseudo-synchronous" or "semi-synchronous" service requests. We designed the blocking functions to be pseudo-synchronous in order to provide a simple blocking interface that helped avoid program deadlock by allowing the DPCL system to continue processing other requests while "blocked".
Figure 3. Blocking function calls (pseudo-synchronous service requests). Calls to blocking functions do not return control to the analysis tool until they either succeed or fail in carrying out the requested service. The blocking functions provide a simpler interface, and so are preferable for applications that don't need to take advantage of the finer level of control available in an asynchronous system. In particular, if the analysis tool is instrumenting a serial application, the blocking functions are probably preferable.
 View figure. View figure. |
Figure 4. Nonblocking function calls (asynchronous service requests). The nonblocking functions are designed to take advantage of the asynchronous nature of the DPCL system. Calls to nonblocking functions return immediately upon issuing the service request, without waiting for a response to the request from the DPCL system. Instead, a callback routine responds to the return value from the system. The nonblocking functions can be harder to program, but enable the analysis tool to leverage the finer level of programmatic control.
 View figure. View figure. |
DPCL callbacks are routines called by the DPCL system when certain messages arrive from a DPCL daemon. When an analysis tool initializes itself to use the DPCL system, one of the things it does is enter the DPCL main event loop so that it can interface asynchronously with the DPCL system. The DPCL main event loop listens to file descriptors and sockets for input; there will be one socket for each remote node to which the analysis tool is connected. Remember that the communication to and from each target application process is handled by a DPCL daemon. A DPCL daemon may send two types of messages to the analysis tool. A DPCL daemon may send a message:
When the DPCL main event loop detects input on a file descriptor that is connected to a DPCL daemon, it calls a dispatch routine for the file descriptor or socket. If the input is on a file descriptor representing a socket connection to a DPCL daemon, the message is examined and the appropriate callback for the message type is executed. Since there are two types of messages that can be sent from a DPCL daemon, there are two types of callbacks -- acknowledgment callbacks and data callbacks. Acknowledgment callbacks are callbacks that respond to the success or failure of an asynchronous, nonblocking, function call. Data callbacks are callbacks that respond to probe data forwarded by the DPCL daemon.
All callback routines have the same parameters. These parameters include:
There are two types of DPCL daemons -- DPCL communication daemons and DPCL superdaemons.
In order for the DPCL daemon processes to be as unobtrusive as possible, we have designed the DPCL system so that only one DPCL communication daemon per user and only one DPCL superdaemon will be running on each host machine at a time. Furthermore, we have ensured that these daemons are not persistent; they will terminate when the analysis tool issues a service request to disconnect from the target application process.
To better understand the purpose and life cycle of the two types of DPCL daemons, it is worthwhile to understand how they are created, used, and destroyed. First, an analysis tool will need to connect to the target application processes. To do this:
If the target application is a parallel application, similar connections and daemons need to be created for each host on which the target application processes are running. Once the analysis tool is connected via the DPCL communication daemon(s) to the target application process(es):
Finally, when the analysis tool is done collecting data, it will need to disconnect from the target application processes. To do this:
Since we have designed the DPCL system so that only one DPCL communication daemon per user will be running on a given host, this means that a single DPCL communication daemon may be coordinating the communication between multiple target application processes and/or multiple analysis tools. The following figure illustrates the possible connection variations that can exist for a single user on a single host machine.
Figure 5. DPCL communication daemon. Each host machine has only one DPCL communication daemon per user. It may coordinate the communication between multiple target application processes and/or multiple analysis tools. Keep in mind that this figure illustrates a single user and a single host machine. Each user connected to a DPCL target application process on the host will have a separate DPCL communication daemon running. Likewise, each user will have a separate DPCL communication daemon for each host that is running target application process(es) to which he or she is connected.
 View figure. View figure. |
The term probe refers to the software instrumentation code patch that your analysis tool can insert into the target application. Probes are created by the analysis tool, and therefore are able to perform any work required by the tool. For example, depending on the needs of the analysis tool, probes could be inserted into the target application to collect and report performance information (such as execution time), keep track of pass counts for test coverage tools, or report or modify the contents of variables for debuggers.
Probes are created by the analysis tool using a combination of probe expressions and probe modules (described next in What is a probe expression? and What is a probe module?). For the purposes of this book, a probe is defined as "a probe expression that may optionally call functions".
A probe expression is a simple instruction or sequence of instructions that represents the executable code to be inserted into the target application. Probe expressions are abstract syntax trees -- data structures that represent the logic to be performed by the probe within the target application process(es).
The term "abstract syntax tree" is one we have borrowed from compiler technology. These data structures are called "abstract" because they are removed from the syntactic representation of the code. For example, an abstract syntax tree for the expression a + (b x c) is identical to the abstract syntax tree for the expression a + b x c (where only precedence rules force the multiplication operation to be performed first).
Figure 6. Abstract syntax tree. This abstract syntax tree formed from either the expression a + (b * c) or the expression a + b * c.
 View figure. View figure. |
Compilers need to create abstract syntax trees from a program's source code as an intermediary stage before manipulating and converting the data structure into executable instructions. Since the DPCL system also needs to create executable instructions (for insertion into one or more target application processes), it also needs to create these abstract syntax trees. When the analysis tool inserts a probe expression into one of more target application processes, the DPCL system uses compilation techniques to manipulate these abstract syntax trees into executable instructions that will run as part of the target application process(es).
From the DPCL programmer's point of view, the procedure for creating a probe expression can be a "building block" task in which smaller probe expressions are eventually combined and sequenced into the full probe expression.
For example, the analysis tool can create probe expressions representing constant or variable values, and then combine these into more complex probe expressions representing simple operations on the values, or function calls that pass the values as parameters to the function. The analysis tool could then take two of these more complex probe expressions and combine them into a single probe expression that represents a sequence of the two existing expressions. Then the analysis tool could join two such sequences into a longer sequence or combine them into a conditional statement. This process of combining and sequencing smaller probe expressions into larger ones would continue, depending on the complexity of the probe logic, until the analysis tool has a single probe expression representing the full probe logic.
The class for creating probe expressions is the ProbeExp class. Constructors of this class enable your code to create probe expressions that represent temporary data variables. Functions of other DPCL classes enable your code to create probe expressions that represent persistent data variables. To create probe expressions to represent operations, the ProbeExp class has overloaded common operators so that expressions written within the context of the class do not execute locally, but instead call member functions designed to create a probe expression that represents the particular operation. Probe expressions to represent arithmetic, bitwise, logical, relational, assignment, and pointer operations can all be created in this way. These probe expressions can then in turn be used as subexpressions in forming other probe expressions -- ones representing more complex operations. Other functions of the ProbeExp class (ones that must be called explicitly) enable your code to create a probe expression to represent a sequence of two existing probe expressions, a conditional statement, or a function call.
Although an analysis tool can create probe expressions to perform conditional control flow, integer arithmetic, and bitwise operations, the programmatic capabilities of probe expressions are rather limited. When more complicated probe logic is needed (such as iteration, recursion, and complex data structure manipulation), a probe expression can direct the target application to call a function in a probe module.
A probe module is a compiled object file containing one or more functions written in C. Once an analysis tool loads a particular probe module into a target application, a probe is able to call any of the functions contained in the module.
As already stated, a probe is a probe expression that may optionally call functions. There are three types of probes; they are differentiated by the manner in which their execution is triggered. The three types of probes are:
Each probe type has different intended uses, and together are designed to enable an analysis tool to efficiently instrument a target application. By "efficiently instrument", we mean "to collect the necessary data and display it in a timely manner while minimizing the instrumentation's intrusion cost to the target application".
Point probes are probes that the analysis tool places at particular locations within one or more target application processes. When placed in an activated state by the analysis tool, a point probe will run as part of a target application process whenever execution reaches its installed location in the code. The fact that point probes are associated with particular locations within the target application code makes them markedly different from the other two types of probes (which are executed at a particular time regardless of what code the target application is executing).
To install a point probe within one or more target application processes, the analysis tool must navigate the source code structure of the target application to identify locations where it can safely install point probes. The analysis tool navigates the source code structure by means of source objects (represented by instances of the SourceObj class); the locations where point probes can be installed are called instrumentation points (represented by instances of the InstPoint class).
Source objects provide a coarse, source-code-level, view of a target application process, and enable an analysis tool to display or navigate a hierarchical representation of a particular target application process. After connecting to a process, the analysis tool can get the top-level source object (called the "program object") for the process; the analysis tool does this by calling the member function Process::get_program_object. This function returns the top-level source object (an instance of the DPCL class SourceObj). Since applications can be quite large, the initial source object provides only a very coarse view of the source structure; essentially, it is just a list of the modules (compilation units) contained in the target application process. Each of these modules is itself a source object and is considered a child of the program source object.
To navigate down into the source structure of a module, an analysis tool gets a reference to one of these module source objects (using the member function SourceObj::child) and expands it (using the SourceObj::expand or its blocking equivalent SourceObj::bexpand). Expanding a module source object returns the additional structure of the module -- including data, functions, and instrumentation points.
It is important to keep in mind that the program object and all its child
module objects reflect the source hierarchy associated with a particular
process only. This means that, in some cases, the analysis tool will
need to navigate multiple source hierarchies (as described in the following
table).
| If the target application is: | Then: |
|---|---|
| A serial program. | The analysis tool need only navigate the target application's single source hierarchy. |
| A parallel program that follows the Single Program Multiple Data (SPMD) model. | Each process in the target application has the same source and,
therefore, the same source hierarchy. The analysis tool need only
navigate a single source hierarchy.
The analysis tool still has the option to either insert identical instrumentation in each of the processes, or else instrument the processes differently. |
| A parallel program that follows the Multiple Program Multiple Data (MPMD) model. | There are multiple programs, and, therefore, the analysis tool will need to navigate multiple source objects. |
Instrumentation points are locations within a target application process where an analysis tool can install point probes. Instrumentation points are locations that the DPCL system determines are safe to insert new code. Such locations are:
Instrumentation points are obtained from source objects, at the function level, using the SourceObj::exclusive_point or SourceObj::inclusive_point functions. Both functions take an integer index value as an input value and return an instrumentation point as a result. The difference between the two is that the SourceObj::exclusive_point function gives the analysis tool access only to instrumentation points that are tied to that particular source object in the source object hierarchy, while the SourceObj::inclusive_point function gives the analysis tool access to all instrumentation points associated with the given source object and all of its lower level source objects in the source object hierarchy.
An analysis tool should use a point probe when it needs to collect data associated with a particular location in the target application's code.
To better understand when it is useful, and when it is not useful, to use a point probe, consider the following hypothetical situation. Say your analysis tool is a profiler that needs to measure the accumulation of floating point counts by function. Say also that this analysis tool is a Java(TM) client that needs to periodically refresh itself to display the newly-collected data to the user. Since the functions are specific locations in the target application code, you would need to use point probes to measure them effectively. In this particular example, you would set up two point probes for each function -- one at the beginning of the function and one at the end. Each time the function starts executing, the first probe would determine the number of floating point instructions executed up to that point. Later, the second probe would determine the number of floating point instructions executed, and, by subtracting the first figure from the second, the number of floating point instructions executed within the function.
So in this example, you would use a set of point probes to collect the data. Keep in mind, however, that it is not enough to simply accumulate collected data within the target application process(es) as we have in this example. Remember that we also need to communicate this information back to the analysis tool. In this case, we have said that our hypothetical application needs to periodically refresh its Java client to display the newly-collected data. We could have the point probes themselves send their collected data back to the analysis tool, but this would not be an efficient solution. You would not, in this example, want to send data back to the analysis tool using the point probes because such probes located in frequently-executed functions could swamp the network with messages and, in doing so, take a valuable resource away from the target application. This solution would be unacceptable, as it would likely slow the target application appreciably; the instrumented version of the target application would no longer be representative of the actual, uninstrumented, version of the target application. While point probes are useful for collecting the data in this example, the actual communication of that data back to the analysis tool would be better handled using phase probes (as described in What is a phase probe?) or one-shot probes (as described in What is a one-shot probe?).
Phase probes are probes that are executed periodically, upon expiration of a timer, regardless of what part of the target application's code is executing. A phase probe, unlike the other two types of probes, must call a probe module function; in other words, a phase probe cannot be a simple probe expression that does not call a probe module function. The control mechanism for invoking these time-initiated phase probes is called a phase.
Phases are the control mechanism for invoking phase probes at set intervals. Represented by instances of the Phase class, phases enable your analysis tool code to specify the particular phase probe(s) to be invoked and the CPU-time interval at which their execution is triggered. The set interval at which a phase is activated to invoke its phase probes is called the phase period. Although the phase period is initially defined when the analysis tool first creates the phase, the analysis tool can later lengthen or shorten the phase period as desired.
A phase can, each time the phase period expires, call up to three phase probes. As already stated, a phase probe must call a probe module function, so the phase is actually triggering calls to up to three probe module functions -- a begin function, a data function, and an end function. While the phase must, in order to be useful, call at least one of these functions, any one of them is optional. At the very least, an analysis tool will usually supply a data function.
When a phase is added to a target application process, it will, once the phase period expires, be activated by the DPCL system. (The DPCL system uses a SIGPROF signal to activate a phase, so be aware that target applications that themselves use the SIGPROF signal cannot be instrumented with phases.) Once the phase is activated, it will call the phase probe module functions that have been associated with it. The first phase probe it calls is the one identifying the begin function (provided one has been specified). Typically, the begin function will perform any setup tasks that may be required. When the begin function completes, the phase calls the phase probe that identifies the data function (provided one has been specified). The data function executes once per datum that the analysis tool will have previously allocated and associated with this phase. Executing once per datum enables the data function to perform the same actions on different data. Each datum, for example, could be a separate counter -- each incremented by the same data function. If the analysis tool does not associate any data with the phase, then the data function will not execute. When the data function finishes executing for the last datum, the phase calls the phase probe that identifies the end function (provided one has been specified). Typically, the end function performs any clean up chores that may be required.
An analysis tool should use phases and phase probes whenever necessary work is best done on a periodic basis. For example, in When should an analysis tool use a point probe?, we described a hypothetical situation in which an analysis tool needed to measure the accumulation of floating point counts by function. While we determined that point probes placed inside functions were the best way to collect data, we also determined that they were an impractical way to send that data back to the analysis tool. We determined point probes would be impractical because such probes located within frequently-executed functions would utilize too much of the available network communication resource, and so slow the target application unacceptably.
In this example, a phase that triggers one or more phase probes at a set interval would be an ideal way to communicate the data collected by the point probes back to the analysis tool. By using a phase, you would be able to tune how often you send updates back to the target application. While you cannot control how often the point probes are executed to gather the data, you can use a phase to govern how often a phase probe is triggered to send the collected data back to the analysis tool. What's more, since the analysis tool can modify the phase period to trigger execution of the phase probe more frequently or less frequently, the analysis tool could dynamically govern how often the data is sent. For example, our hypothetical analysis tool could also monitor network traffic or the target application's performance to determine if the intrusion cost of the data being sent from the phase probes is too great. If so, the analysis tool could modify the phase period so that the data is sent less often.
A one-shot probe is a type of probe that is executed by the DPCL system immediately upon request, regardless of what the application happens to be doing.
An analysis tool should use a one-shot probe whenever it wants to explicitly and immediately execute code within the target application process on a one-time basis. Most commonly, analysis tools would use one-shot probes to:
For example, in When should an analysis tool use a point probe?, we introduced a hypothetical analysis tool that, in order to measure the accumulation of floating point counts by function, installed a set of point probes to collect this data. We continued this same example in When should an analysis tool use phases to invoke phase probes? by using a phase probe to minimize network traffic by only periodically sending the data back to the analysis tool to be displayed to the operator. Suppose now that, as the creator of this analysis tool, you wanted to add a "Refresh" button to the tool's graphical user interface so that the operator could force the tool to update itself with the most current information. To do this, the analysis tool could, whenever the operator clicks on the "Refresh" button, execute a one-shot probe to send the most recently collected data back to the analysis tool for display.
Our original motivation for creating the DPCL system came from the observation that customers were often asking for more application performance analysis tools than tool suppliers had the resources to build. High performance application developers were asking for tools that would provide detailed, accurate information about I/O usage, cache (and other memory usage), CPU and functional unit usage, message passing and synchronization, and operating system effects. Furthermore, they were asking for application profiles to identify problems, and event traces to determine the root causes of problems.
However, while programming tools were becoming more expensive to build and maintain, available tool development resources were shrinking rapidly. More tools were needed, but fewer tools could be created. So, in creating the DPCL system, our goals were to:
Not only would you have to create an application from scratch to do all that, but, since analysis tools must be very careful not to adversely effect the target application's performance, you must manage to do all these things in such a way that the interference, or "intrusion cost", to the target application is minimal. This is essential, because if the intrusion cost is too great, then the data you're collecting from executing the instrumented version of the target application is no longer representative of the actual, uninstrumented program.
By building your analysis tool on top of the DPCL system, however, you are able to easily leverage its capabilities and thus can spare yourself the burdensome programming chores outlined above. What's more, by saving you the time and effort normally associated with developing analysis tools, the DPCL system effectively reduces the cost of developing new tools.
This ability to make and change data collection decisions during execution is unique to dynamic instrumentation. All other methods of instrumentation require you to make data collection decisions before running the program, and often before compiling or linking the program. Such restrictions often result in one choosing to gather more data than is actually needed, thus increasing the intrusion cost of the instrumentation.